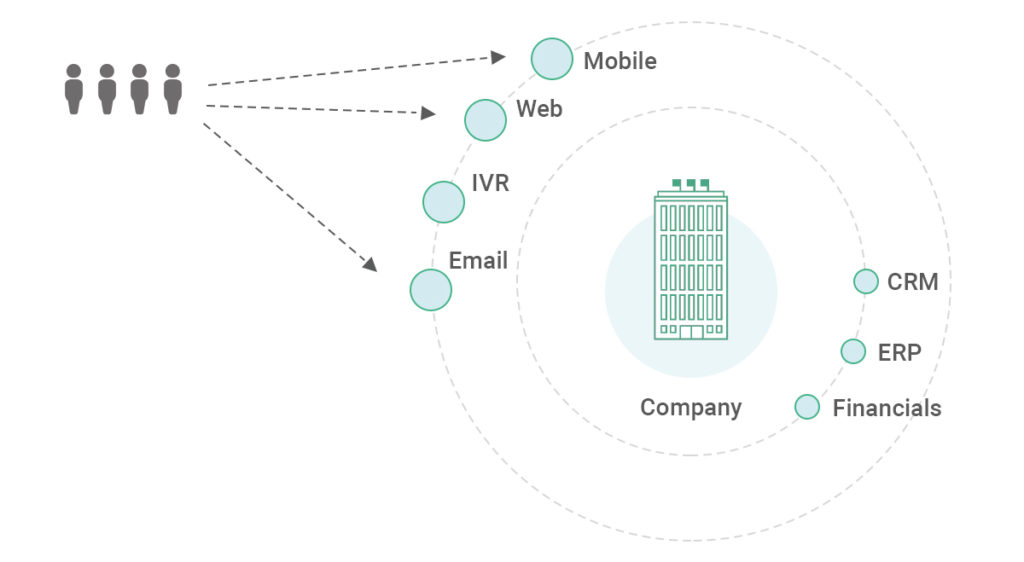
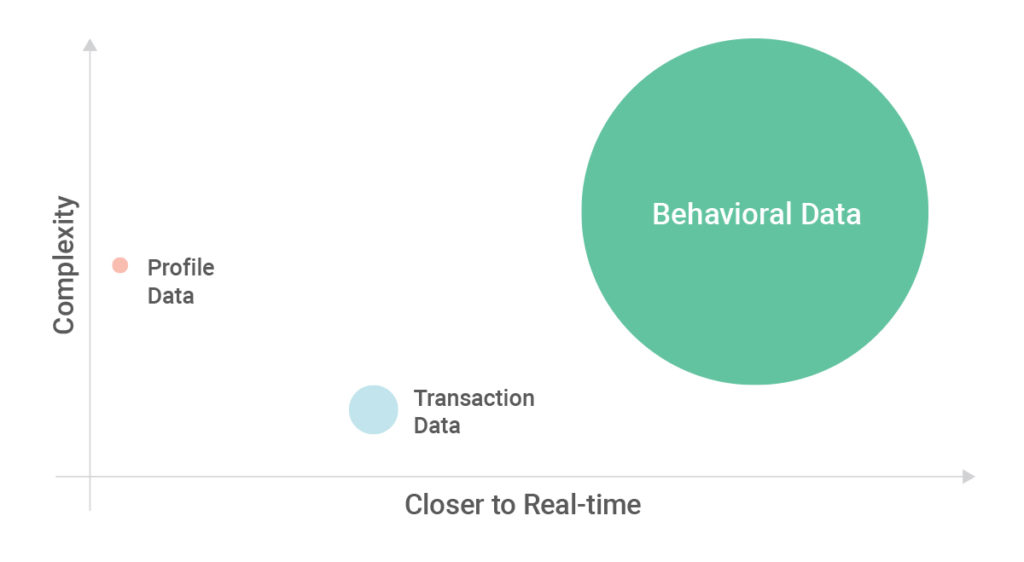
There are three main types of data about customers: who they
are (profile data), what they do (transaction data), and how they interact (behavioral
data). Most enterprises already use profile and transaction data in their
analytics and data science initiatives. Very few companies today, however, take
full advantage of their behavioral data, which includes browsing history,
search behavior, online purchases, downloads, and overall activity across all
of your platforms.
The businesses that have cracked the code on behavioral data aren’t hard to pick out — behemoths like Amazon, Netflix, Uber, and Airbnb are market leaders for a reason. These companies have built reliable and scalable data pipelines that unify massive volumes of behavioral data coming in from their customers every minute of every day; leverage this data to create a single, unified view of all customer interactions; and scale business use cases with AI and machine learning.
What Makes Behavioral Data Hard to Work With
The sheer amount of behavioral data that consumers generate online each day is exactly what makes it so useful to companies. It’s also, of course, what makes this data so difficult to process and consolidate. One of the most commonly available types of behavioral data is clickstream data generated by website activity, which is three to four orders of magnitude more complex than transaction data. For illustration, each customer interaction will typically have tens to hundreds of clickstream data records for every transaction record. And while most transaction records may have dozens of fields (e.g., transaction ID, product ID, quantity, amount, and other product-related fields), a clickstream record will have close to 1,000 fields with a mix of structured and unstructured data like URLs and page names.
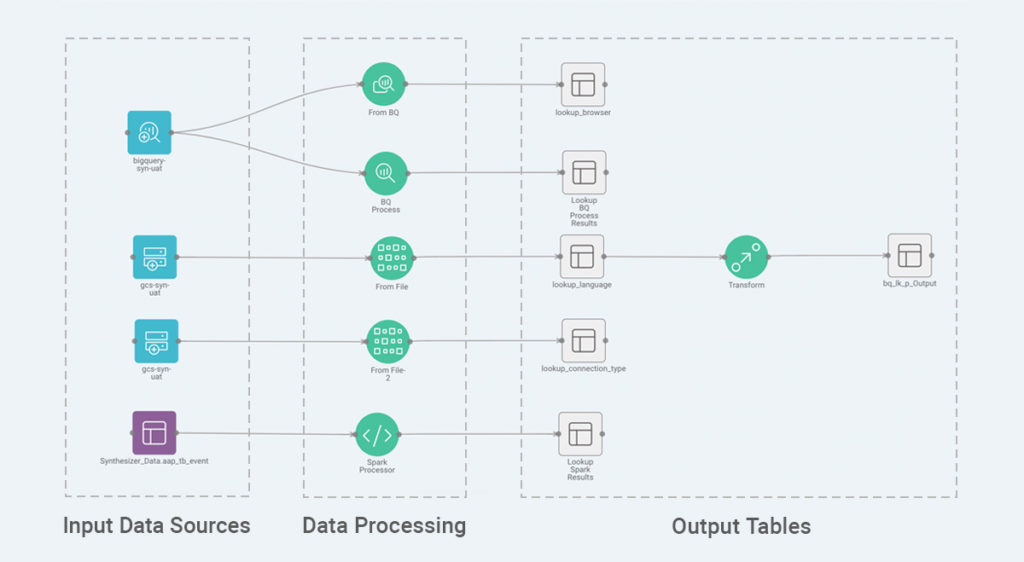
Key Components of a Data Pipeline
A data pipeline is typically a complex chain of an arbitrary number of processes that manipulate data, where the output data of one process becomes the input to the next. Each process will consist of one or more data inputs, one or more data outputs, and transformations such as filtering, data cleansing, enrichment, and aggregations.
Best-in-class data pipelines meet three requirements:
- They are reliable. A reliable pipeline delivers data in a consistent and timely manner. It ensures that data is not lost as it moves across the pipeline. It conforms to a Service Level Agreement and scales gracefully.
- They are resilient. A data pipeline must anticipate and address common failures. Unanticipated failures, rare as they may be, should have an automated recovery process to notify, diagnose, and repair any issues.
- They are configurable. A data pipeline should follow an abstracted framework that shares code with all processes. It should not require engineers to write custom code for each process that will result in the need to maintain pipeline jungles.
What Makes Syntasa’s Behavioral Data Pipelines Special?
Syntasa’s platform is designed to make it simple for enterprises to build behavioral data pipelines that provide better analytics, better decisions, and better actions.
Because pipelines run continuously, they ensure you have the timeliest data – unified for each individual customer. You can add your own customized Machine Learning models to your pipeline to make better decisions on an ongoing basis. And by adding Activation endpoints to your pipeline, you can implement personalized recommendations on your website, improve advertising effectiveness in your digital media, and more precisely predict the likelihood of a customer’s purchase, activation, or churn.
On a more technical note, Syntasa’s pre-built data pipeline apps use several levels of abstraction to maximize code reuse. These abstractions include data sources, structures, and transformations and leverage commonly used open source technologies. While our schema is flexible and configurable, we also provide a sample to help you get started quickly.
How You Can Be Sure That Syntasa’s Pipelines Are Reliable
We ensure our reliability by building audits into every stage of the pipeline, as well as providing guardrails in the form of monitoring and notification. Some data sources provide extra reliability. For example, when building a pipeline using data from Adobe Analytics, we use Adobe Audit to ensure that no data is missing and guarantee that all data is collected successfully. This audit process also displays which data has been collected, why it was collected, and to what extent we can depend on this data to be accurate.
We further deliver reliability through these design principles:
- Once processed, data is made available for others
to consume at an agreed time.
- Data can be expected to match its source at a rate
of 99.9% or greater.
- We allow you to define critical business metrics
(like conversion rates or clickthrough rates) that the system will monitor and
raise alarms if they drop below their minimum expected threshold.
- We track the state of new and modified partitions. This allows us to be fault-tolerant and identify missing or changed data.
How You Can Be Sure That Syntasa’s Pipelines Are Scalable
Scalability is an issue for any organization that deals with a substantial amount of data. Syntasa works with customers who have mammoth scales of data. For example, one of our customers (a global sportswear company) processes five terabytes of data each day.
We utilize native cloud services to scale gracefully and process unexpected spikes in traffic at a moment’s notice. Syntasa’s software runs in your environment, whether that is a virtual private cloud like AWS, GCP, or Azure, or on-premises Hadoop clusters.
You can also employ Spark within the Syntasa framework to query, analyze, and transform data quickly and at scale. Spark offers developers an API for Scala and its programs work quickly to execute programs, facilitating interactive data analysis.
We further deliver scalability through these design principles:
- We process and deliver data on time even when there
are spikes due to seasons, holidays, special events (like Black Friday), or new
product releases.
- We have built-in support for daily and hourly partitions.
Why You Should Get Started Building Your Own Behavioral Data Pipelines with Syntasa
Companies like Airbnb, Amazon, and Uber have taken it upon themselves to build data pipelines to process their vast amounts of behavioral data – and now employ a large team of Data Engineers with deep cloud and big data expertise in order to do so. Most enterprises realize this kind of project will be prohibitively costly and time-consuming, however, so they try to cobble together a solution from existing tools. Most look to Extraction, Transformation, and Loading (ETL), and while those tools successfully deliver on these requirements for smaller datasets like profile and transaction data, they cannot scale to handle the vast amounts of clickstream and other behavioral data.
While it’s true that it’s not easy to build a reliable behavioral data pipeline from scratch, you certainly don’t have to. Syntasa’s platform gives you the ability to get started in days so you can deliver value to your bottom line in a few short weeks.
Looking for help? We’ve created a guide for Data Engineers titled Key Considerations When Building Pipelines for Behavioral Data. Take a look at it, share it with your team, and consider starting a free trial of Syntasa’s Customer Intelligence Platform today.
Charmee Patel
Head of Innovation and Data Science, Syntasa
Charmee Patel leads Product Innovation activities at Syntasa. She has extensive experience synthesizing customer, visitor, and prospect data across multiple channels and scaling emerging big data and AI systems to handle the most demanding workloads. This experience guides her work helping clients deploy innovative ways to apply AI and Machine Learning to their marketing data and developing the next generation Marketing AI Platform.
Sarath Botlagunta
Sarath Botlagunta is an experienced Big Data Architect, currently managing the Platform Engineering team at Syntasa. He has strong experience building complex data analytics and machine learning products, using big data, machine learning, and cloud technologies. He has held previous roles at Corelogic, IBM Labs, and Cognizant, where he worked on creating complex data ingestion pipelines, data transformations, data management, and data governance at the enterprise level. This experience helps him drive the engineering aspects of product development at Syntasa.